
Правильная индексация страниц сайта в поисковых системах одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года - robots.txt.
Что такое Robots.txt?
Robots.txt - служебный текстовый файл на сайте, содержащий инструкции для поисковых роботов какие страницы разрешены для сканирования, а какие нет. Но это не является прямыми указаниями для поисковых машин, скорее инструкции несут рекомендательный характер, например, как пишет Google, если на сайт есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индексацию ресурса без файла Robots.txt и с ним.
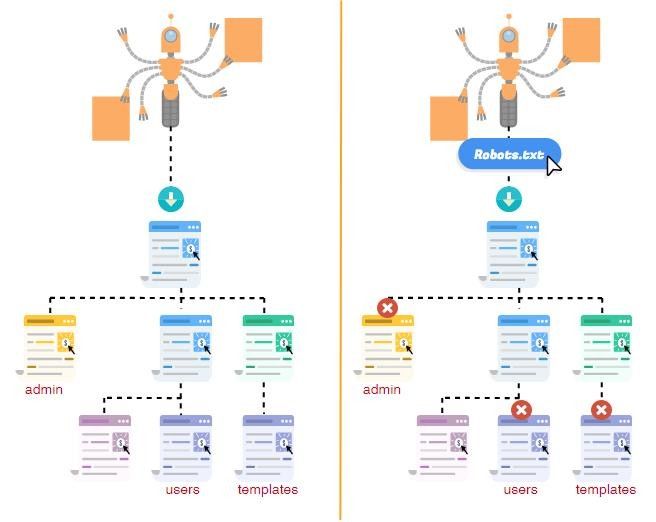
Что следует закрывать от индексации:
- служебные страницы сайта
- дублирующие документы, которые нельзя исключить из структуры сайта иным способом
- приватные данные (страницы авторизации и регистрации, корзины, страницы оформления заказа)
- результаты поиска по сайту
- страницы сортировок
- сравнения товаров
Как создать и добавить Robots.txt на сайт?
- Создайте в текстовом редакторе, например, в Notepad++, обычный текстовый файл, следуя синтаксису стандарта. На некоторых CMS можно создать robots с помощью плагина.
- Текст внутри файла должен быть написан латиницей, для кодировки файла подойдут стандарты ASCII или UTF-8
- Добавьте файл в корневую директорию сайта
- Проверьте доступность файла по адресу: http://www.site.ru/robots.txt
- Проверьте соответствие robots.txt и Sitemap.xml (в Sitemap не должны присутствовать закрытые в роботс страницы)
- Протестируйте корректность директив файла с помощью Яндекс.Вебмастер и инструмента проверки файла robots.txt в Google Search Console. В сервисе Яндекса можно проверить файл до его загрузки на сайт.
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с различными параметрами.
Директива User-agent
С помощью данной директивы можно указать для какого робота поисковой системы будут заданы нижеследующие рекомендации. Если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила. Файл роботс должен начинаться с этой директивы. Для обозначения сразу всех краулеров можно воспользоваться следующей строчкой:
User-agent: *
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot — основной робот Google;
- YandexBot — основной краулер Яндекс-поиска;
- Googlebot-Image — робот картинок;
- YandexImages — робот индексации Яндекс.Картинок;
- Yandex Metrika — робот Яндекс.Метрики;
- Yandex Market— робот Яндекс.Маркета;
- Googlebot-Mobile —индексатор мобильной версии.
Директивы Disallow и Allow
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Disallow - директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: /site/
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru/site/
- Для запрета папки сайта следует указать следующее:
Disallow: /folder/ - Для запрета только одного файла нужно написать:
Disallow: /folder/img.jpg - Если нужно запретить файлы только определенного разрешения:
Disallow: /*.css$ - Allow напротив является разрешающей инструкцией для индексации.
User-agent: *
Allow: /site
Disallow: /
Такая инструкция запрещает индексировать весь сайт, за исключением папки site.
При выборе запрещающей директивы для страниц, которые не должны участвовать в поиске, если их адреса содержат GET-параметры, более эффективно использовать межсекционную директиву Clean-param, которая позволяет передавать основному URL или сайту некоторые накопленные показатели.
Директива Sitemap
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site.com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Устаревшая директива с 2018 года. В Google директива никогда не учитывалась, в Яндексе служила инструкцией роботу Яндекса для указания главного зеркала сайта.
Disallow: /site/
Host: site.ru
Сейчас 301-й редирект полностью заменяет директиву Host. Важно, чтобы на всех не главных зеркалах сайта стоял 301-й постраничный редирект на соответствующие страницы главного зеркала.
Директива Clean-param
Clean-param дает возможность запретить для индексации страницы сайта, которые формируются с динамическими параметрами. Такие страницы могут содержать один и тот же контент, что будет являться дублями для поисковых систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Рассмотрим пример, на сайте есть динамические страницы:
- https://site.ru/promo-odezhda/polo.html?kol_from=&price_to=&color=7
- https://site.ru/promo-odezhda/polo.html?kol_from=100&price_to=&color=7
Для того, чтобы исключить подобные страницы из индекса следует задать директиву таким образом:
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Директива Crawl-delay
Устаревшая директива, с 22 февраля 2018 года не учитывается Яндексом. Ранее Crawl-delay использовалась для снижения частоты скачивания документов с сайта и оптимизации нагрузки на сервер
Чтобы задать скорость, с которой роботы будут загружать страницы сайта, Яндекс рекомендует использовать инструмент "Скорость обхода сайта" в Яндекс Вебмастере в разделе Индексирование. В Google обход роботы заканчивают автоматически, если фиксируют ошибку или замедление реакции сервера.
Disallow: /site
Crawl-delay: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки, не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела)
- Параметры директив необходимо указывать в одну строку
- Правила в роботс указываются в следующей форме: [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать “;”
- Пустая строка трактуется как конец директивы User-agent, если нет пустой строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указывать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на след строке тоже следует поставить #)
- Robots.txt нечувствителен к регистру в названиях директив, но учитывает регистр в написании подстрок (имя или путь до файла, имя робота)
- Если файл роботс имеет вес более 32 Кб или по каким-то причинам недоступен или является пустым, то он воспринимается как Disallow: (можно индексировать все)
- Для каждого раздела и файла необходимо указывать одну директиву
- В директивах «Allow», «Disallow» в параметре директории сайта указываются со слешем (например, Disallow: /site)
- Использование кириллицы в роботс не допускаются. Для указания имен доменов необходимо использовать Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта
- Чтобы не перегружать файл, рекомендуется отслеживать и удалять неактуальные директивы.
Спецсимволы robots.txt
При указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Disallow: /store/*.php # запрещает '/store/ex.php' и '/store/test/ex1.php'
Disallow: /*tpl # запрещает не только '/tpl', но и '/tpl/user'
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *. Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Disallow: /site$ # запрещено для индексации '/site', но не запрещено'/ex.css'
User-agent: *
Disallow: /site # запрещено для индексации и '/site', и '/site.css'
User-agent: *
Disallow: /site$ # запрещен к индексации только '/site'
Disallow: /site*$ # так же, как 'Disallow: /site' запрещает и /site.css и /site
Особенности настройки robots.txt для Google
Для Google особенность состоит в том, что сама компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. В таком случае, робот примет такой вид:
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *.js
Host: www.site.com
С помощью директив Allow роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
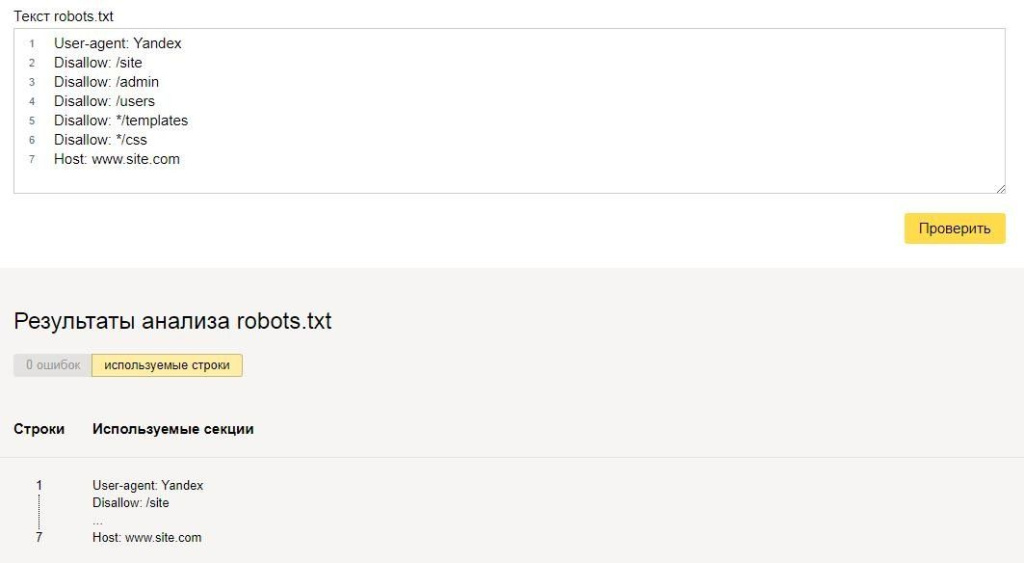
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера:
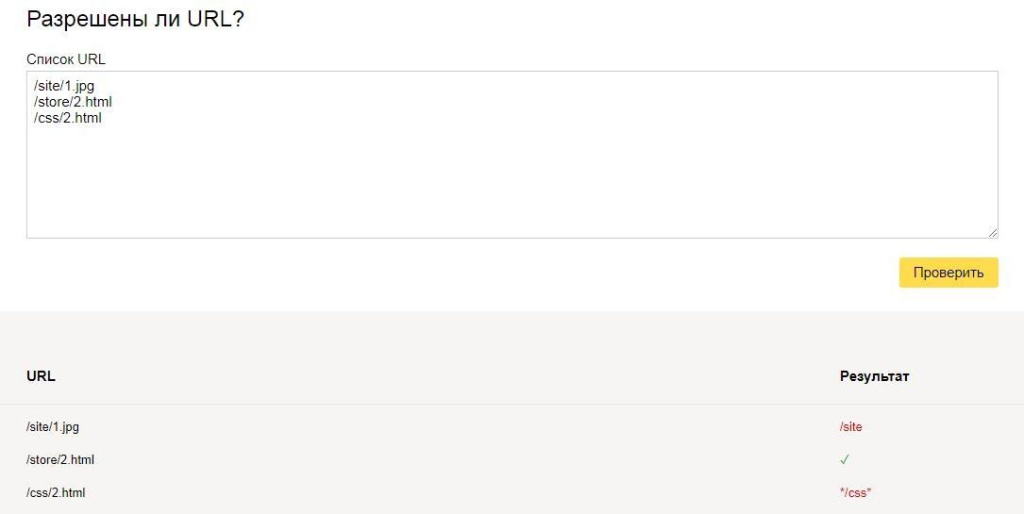
Также при помощи данного инструмента можно проверить разрешены или запрещены к индексации страницы:
Еще одним инструментом проверки правильности роботс является “Инструмент проверки файла robots.txt” в панели Google Search Console:
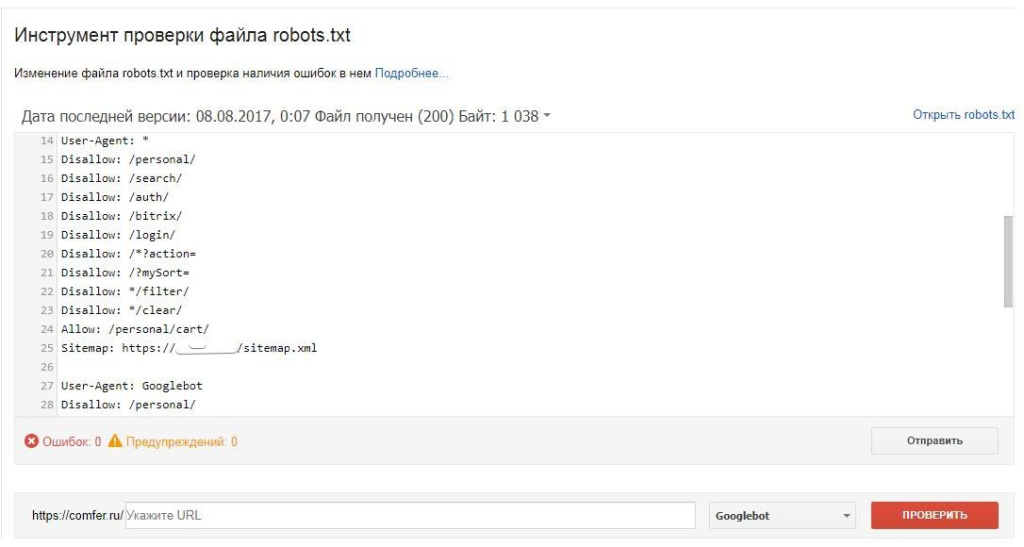
Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Пример настройки роботс для WordPress
Правильный robots.txt для Wordpress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Host: www.site.ru
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *.css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap1.xml
Пример настройки роботс для Bitrix
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексация дублей страниц сайта.
Чтобы избежать подобных проблем, которые могут повлиять на позицию сайта в выдаче, следует правильно настроить файл robots.txt. Ниже приведен пример robots.txt для CMS 1C-Bitrix:
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
HOST: https://site.ru
User-Agent: *
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Host: site.ru
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен быть составлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Allow: *.css
Allow: *.js
User-Agent: *
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots.txt для Джумлы должен быть составлен таким образом:
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Host: www.site.ru
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www.site.ru/sitemap.xml



